
How do we achieve continuous delivery?
To quote Jez Humble:
Continuous Delivery is the ability to get changes of all types—including new features, configuration changes, bug fixes and experiments—into production, or into the hands of users, safely and quickly in a sustainable way.
The ultimate goal of continuous delivery is to minimise the iteration time of the code-test-deliver-measure experimentation cycle. Increasing deliverable throughput in this way is the key to not only more feature work being delivered but higher quality code as well. This might seem counter-intuitive at first but code is fixed and polished through that same cycle and less time spent on deployment is more time spent on designing quality code. You can read Jez Humble’s website and/or book for the details and data.
Having decided that continuous delivery is an ideal we want to pursue we had to decide how. The high-level requirements were:
- Software must be easily testable, which means it must be loosely coupled.
- Delivery must—under normal circumstances—require minimal human interaction.
- Delivery—from commit to production—must be fast. Preferably under 10 minutes.
- Rolling back a deployed feature if it is found to be broken or unwanted must be trivial.
While it is not the only possible solution after deliberation we settled on a microservices architecture. Microservices enforce loose coupling, plus it’s easier to develop fast and reliable deployment pipelines if they only have to handle small packages.
However, microservices introduced a new problem: if adding a feature was often going to require adding a new, independently deployed and hosted service then that process had to be fast and not require any specialist knowledge. Demanding that every single developer in the company learn the intricacies of maintaining Puppet configuration for all their services would have been impractical and more than a little cruel. We set ourselves the goal that feature teams should be able to set up a new service in under four hours, which meant:
- Developing services should not require knowledge of the infrastructure and changing infrastructure should not require detailed knowledge of the services running on it. If we need to change the hostname or port a service runs on it should require no changes to the service itself.
- All project configuration—from build process to health monitoring—must be contained within the project repository. Anything else introduces hidden dependencies for deployment that threaten to break the pipeline and require specialist knowledge to debug.
- The above configuration should be declarative and not require adding dependencies to the project. We didn’t want our Elixir or .NET projects to have to include a full npm configuration just to use gulp to run their build steps.
We haven’t entirely reached these lofty goals but we’re much—very much—closer than we used to be thanks to containerisation, service discovery and a couple of bespoke tools. So let me introduce you to our deployment pipeline.
Containerisation
Spanish philosopher José Ortega y Gasset famously wrote “I am myself and my circumstances” to express that no life can be separated from the context it occurs in. In much the same way the source code of a program cannot fully describe the function of that program without the context it will be compiled and run in. Most unexpected behaviour during deployment comes from build environments being different than expected. To make deployment repeatable, we need to make a program’s context repeatable. That’s where Docker comes in.
Docker essentially allows you to specify a “source code” for a program’s context that can then be “compiled” to an image and run as a container—the details are fascinating but I won’t go into them here. This means that once we have tested an image we can have high confidence that it will perform equally well in every environment it is deployed to.
Additionally, Docker (through the compose utility) allows you to specify deploy configurations made up of multiple containers all linked in a private network and DNS that allows services that depend strongly on each other to be deployed and scaled together. For example, our visualization configuration storage consists of a thin API over CouchDB. The in-house API is deployed linked to the official CouchDB Docker image from Docker Hub which is accessed in the API code simply as db:5349.
Service discovery
To be fully context-agnostic, deployment should be able to happen to any host on the network on whatever port the host happens to have free. This presents a challenge: how do services link up when their network locations are fluid? You need a reverse proxy (we use nginx) and a way to keep its configuration up to date in a changing service landscape.
We use HashiCorp’s Consul to store and monitor service state. Each host has a consul instance that receives information about the containers running on it from registrator, grouping them into services and tags. We currently use tags to indicate environment (integration vs production) and colour (blue vs green).
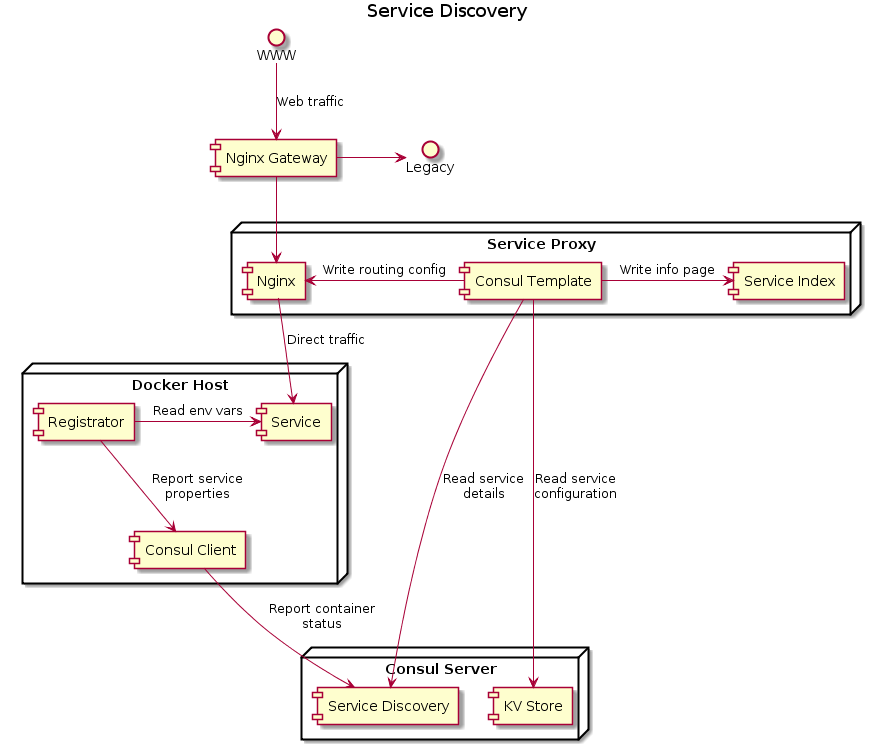
Fig 1. The full service discovery infrastructure
HashiCorp provides a templating system with an application that monitors consul for changes which we use to auto-generate the reverse proxy configuration and reload it when it changes. This system is extended with flags in consul’s versatile key-value store where we store—for example—aliases. With this setup blue/green deployments become a simple question of sending an HTTP PUT flipping the production alias from green-production to blue-production once all checks pass.
What a deployment looks like:
- Build Docker image.
- Test that image in isolation.
- Push that image to the in-house image registry.
- Pull all images you need to deploy linked.
- Deploy them to a test environment.
- Run automated tests against the container system.
- Upload service configuration to Consul API (if changed).
- Deploy the containers to all hosts, tagged with the offline colour.
- Wait until they are all responding and passing automated checks.
- Flip environment alias to point at the offline colour.
- The new build is now online.
What service developers need to know:
- The hosts they have resources assigned in. For now. Eventually we plan to move to a docker cluster where resources are allocated and monitored automatically so teams won’t even need to know that.
- The proxy URI’s of all services their service depends on. These are all available with descriptions in an auto-generated service catalogue and they do not change.
That’s not much, compared to needing to know the IP address, port, and environment of not only the service you’re deploying but all services you’re going to need. Developer time and attention is an expensive resource and everyone is happier when it is focused on developing new features, not orchestrating dependencies on remote hosts.