
This post discusses how we take our data from its raw state to something that joins the rest of our records in a sub-second search index for nearly 3 billion records.
Background
At findmypast, we have the ability to flexibly search our billions of records using a Solr index. But just how does the data get in there and what have we done to make the Search experience so adaptable and responsive? We’ll take a journey with a record to see how it starts from ink on a page in a book, to the key to discovering your past. (Maybe!)
A Long Time Ago…
Over the last few hundred years various hand-written records have been collected about people. From censuses to birth records, army medal records to passenger lists, court documents to electoral rolls, there are billions of hand-written or typed lines with names, dates, places and events. Organisations like The National Archive, Family Search, and Billion Graves all work with us to supply raw data to us to publish on our site.
The raw data comes in all sorts of formats: Database dumps; PDF books; CSV files; Images. We use techniques like OCR + image processing, teams of transcribers copying text into a computer, and database import scripts to turn that raw data into a digital format we can start working with.
Stage 1 - The Gold Dataset
Data really begins life for us in Search once it is turned into ‘Gold’ data in a MySQL database. (Although the process of scanning and OCR of delicate paper pages from books which are decades or sometimes more that a hundred years old, almost faster than you watch is interesting too - but another post…)
The gold databases take all sort of shapes - there’s no real prescribed structure except for a few key fields like a date and a title for the dataset.
Let’s start with a record for Malcolm Reginald Clark (b. 1925), mentioned in the 1939 Register as an evacuee along with his brothers Douglas and Peter just before the outbreak of WWII. He’s my grandfather.
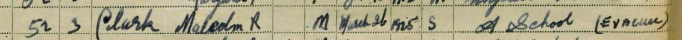
He’s listed as a row in a table in our MySQL Gold Data store.
First, we assign the record a unique record id that is made up from a supplier code, a code for the dataset, and an Id within that dataset.
TNA/R39/2647/2647E/006/18
Next, we attach to the record the Id of any image that accompanies the record.
TNA/R39/2647/2647E/006
And any other keys that might tie that record to another (for example, a household Id that other people who lived with them also share)
3494960
Then there are a whole bunch of cleaning and standardisation processes that take place that make sure any place-names, dates, names, and a myriad of other fields follow prescribed patterns and spellings of our other data.
Our Gold Data is ready to be used.
Stage 2 - The Dataset
Our Data Team create a metadata definition that describes how we should index and search all the information within this dataset.
At findmypast, our search is powered by Solr which is an amazingly flexible storage solution that allows us to store many different shapes of data together and search them ‘as one’.
For our record in the 1939 Register, we decide to make a lot of information from the record searchable by the user: FirstName; LastName; Full BirthDate; Location; Gender; Marital Status; Occupation; Other Household Member Names; Official Ref. Number.
A few fields like Ledger Code are judged not useful for searching and are left as display-only fields.
The columns in the Gold Data table are mapped to the fields we want to use in our Solr index using a simple SQL statement:
SELECT
forename AS FirstName,
LastName,
DATEPART(DAY, BirthDate) AS BirthDay,
...
FROM 1939_Register
Stage 3 - The Ingest
We’re ready to get our data into Solr. We use our Ingest Tool to select our data from the MySQL Gold Data and send it to our Ingest API that will store it in Solr.
The Ingest Tool runs the SQL statement and sends batches of messages to the API containing hundreds of records at a go to store. Each record is represented as a JSON object:
{
FirstName: "Malcolm Reginald",
LastName: "Clark",
BirthDay: 26,
...
LedgerCode: "EPCF",
RecordMetadataId: "1939_register"
}
Our API parses this message and, using the metadata for the dataset, works out what needs to be sent to Solr. It also augments this information with extra data such as the category & sub-category, an estimated BirthDate, & DeathDate (where not specified explicitly in the record), and the Record Provider information.
Using the metadata it works out the field types for each field too.
A message to Solr might look like this:
{
FirstName__fname: "Malcolm Reginald",
LastName__lname: "Clark",
BirthDay__int: 26,
...
KeywordsPlace__facet_text: [
"England",
"Isle of Wight",
"Newport"
],
RecordMetadataId: "1939_register"
}
The suffixes to each field tell Solr how to process and store it.
It sends posts to Solr with the information to store. And here’s where it gets more interesting…
Solr Search Strategy Setup
Solr is very flexible and because it follows a noSQL approach, you can store different shapes of document all together. In addition, because it uses a Lucene index, it can do more than just store simple strings, numbers, dates etc.
Strings can be stored as-is with little intelligence, or as processed text that can be broken down into token words, synonyms added, plural words stemmed to the singular, and a whole host of other manipulations.
Our record for Malcolm Clark is stored with all the other records. His last name is stored along with synonyms like Clarke, his first name is broken down into two terms, one for Malcolm and one for Reginald, everything is lower-cased for ease of searching, and fields that are multi-valued are separated out.
Solr Shards
Solr documents largely live in isolation from each other. In a relational database there are foreign keys that tie records together. In a graph database, there are relationships that tie nodes together. You don’t get that concept (much) in Solr.
Because of this, sharding (or the act of splitting a data store down into smaller pieces) is very much a first-class citizen.
Sharding is powerful in Solr and there are a few choices you can make to maximise the efficiency and speed you get.
You can opt to leave it all up to Solr. Simply tell it how many shards you want to split the index into and it will create little indexes for you that all work together as a cloud. When you store data, fire it at the cloud and let Solr decide how to balance the load and where to store it, based on a hash of the key.
The downside of this approach is that all parts of the cloud have to reply to a query. If you search for documents where the LastName equals Clark, all shards have to give their response before a final count can be returned.
But this serves very well for relatively small indexes of a few million records. The load is spread out over a number of Solr nodes and so long as there’s not too much load on them, they all respond very quickly.
For larger collections such as ours, you can impose your own sharding strategy. At findmypast, we looked at the shape of queries to our site and realised that most people search our records using a name of a person they’re looking for.
So we decided to shard our index by LastName. Names beginning with AAA-ARB are stored in shard 1, ARC-BAC in shard 2, and so on up to WIZ-ZZZ in shard 48. Records without a last name go into a ‘Default’ shard.
We split our index into 49 separate smaller surname-based indexes!
We do this to make our searches faster. When a search comes in with a surname, we only need to query a small part of the total to look for records. If a search comes in without a last name, it’s still fast as we benefit from parallel processing in our smaller search indexes.
But it’s even more efficient than that
Because Solr works as a load-balanced cloud, we have multiple copies of each shard - the one doing the least work is chosen to respond. In total we have 156 separate shards just serving record searches. Then there’s 8 shards for addresses and image searches, 106 shards serving our hint queries from our Family Tree. And a whole other set of infrastructure serving our British Newspaper Archive records.
Here’s a crazy screenshot showing a representation of our record-search Solr cloud:
Next Stage - Searching
Hmm. There’s still a huge amount to talk about. Filter caches, Riak document stores, Solr plugins, Memcached searches… They all contribute to making our Search platform as fast and as extensive as it is. This is going to need a ‘part 2’ post to go through them.
Malcolm Clark is there waiting to be discovered and we’ll go through how we do that next.
But I hope you can see from this high-level look at Search that we have a big investment in the platform that means we can give customers what they want in a fraction of a second.
Alex Clark
Search Developer
Findmypast
aclark@findmypast.com
www.findmypast.co.uk