

High Availability (HA) means that users can run their critical production services without worrying about a database becoming unavailable due to the failure of a database component. It improves the reliability of running a database by minimizing downtime and ensuring that the service is never down for more than a few seconds in the event of a failure.
A HA database cluster includes a source database instance (master) and one or more replicas (slaves). If the master becomes unavailable, an automatic failover is initiated to one of the slaves, with the slave promoted to the new master. When the old master becomes available the HA solution, should implement automatic recovery to synchronize it with the new master and so become another slave.
We looked at a number of solutions for implementing HA with Postgres. One solution Pgpool recommended in Postgres’s own Wiki turned out to be a disappointment due to poor documentation, flaky performance and the lack of support for automatic recovery. An alternative commercial solution ClusterControl had some nice features, but the free version didn’t support automatic failover and recovery, and the premium version was prohibitively expensive. The next option investigated was Patroni, an open source solution which had good documentation and from testing proved to reliably implement automatic failover and recovery . A shame this wasn’t in the list of recommended solutions on the Postgres Wiki!
Patroni
Patroni is a solution developed by zalando, an e-commerce company based in Berlin. It is used by GitLab, Red Hat, IBM Compose and Zalando, among others.
It can run on VMs (or bare-metal), docker containers or kubernetes. For simplicity, we tested Patroni on VMs. Patroni runs on the same machine as the databases so it can control the postgresql service.
Patroni supports three synchronisation modes: Asynchronous mode, Synchronous mode, and Synchronous mode strict.
Asynchronous mode is performed by postgres streaming replication. It does not rely on slaves to update the master, so there is the possibility of the databases getting out of sync in case the master goes down.
Synchronous mode is controlled by patroni and prevents the former from happening as it keeps the slaves in sync with the master. However, when there are no slaves, the master is switched to standalone, and will accept write commits. This might cause inconsistency if a slave comes up, as although the slave is not going to be promoted to master, it will still be able to serve out of sync data for reads 1.
Synchronous mode strict is also controlled by patroni but the master will not accept commits unless there is a slave it can synchronise with, preventing the former issue.
Consul, HAProxy & Keepalived
For HA it’s important to store the state of the cluster in a reliable and distributed manner. We already use Consul for this purpose with our Kubernetes cluster, so it made sense to re-use this solution for Patroni.
For a database cluster it would be cumbersome to manually track the endpoint a client should connect to. HAProxy simplifes this by providing a single endpoint forwarding connections to whichever node is currently the master. An additional benefit is that HAproxy can be configured to provide a read-only port that will connect to slave, allowing distribution of read-only queries across the cluster.
At this stage if we only used one instance of HAProxy then this would be a single point of failure and our solution would not be HA. The answer, as always, is to have multiple HAProxy instances, but to use Keepalived to provide a virtual IP that points to the live HAProxy.
Backups
HA does not obviate the need for backups. For example a malicious query might wipe your important data and this would instantly be replicated to your slaves.
Barman is our tool of choice for performing backups of Postgres DBs. The full backups are performed overnight with continuous archiving of the write ahead log files allowing point-in-time-restore. We configured Barman to use an SSH connection on HA proxy and a postgres connection for WAL archiving. We hoped to use a read-port port on HAProxy, so that continous archiving load would occur on a slave. Unfortunately, Barman does not support this configuration 2.
Migration to the cluster
In order to migrate an existing single DB to a HA cluster we developed Ansible 3 scripts to install Patroni, configure Consul, Barman and HAProxy. The Ansible playbooks were executed many times on a test cluster to prove their idempotency and gives us confidence in the migration process.
The migration followed these steps:
- Create two new VMs.
- Run the postgres playbook on the current database node which will now become cluster master.
- Run the postgres playbook on the VMs which will become the cluster slaves.
- Run the HAProxy playbook to configure HAProxy to provide read-only and read/write ports.
- Configure Barman to take backups.
- Switch clients to use the read/write or read-only ports provided by HAProxy.
Following the migration the architecture of the cluster looked like:
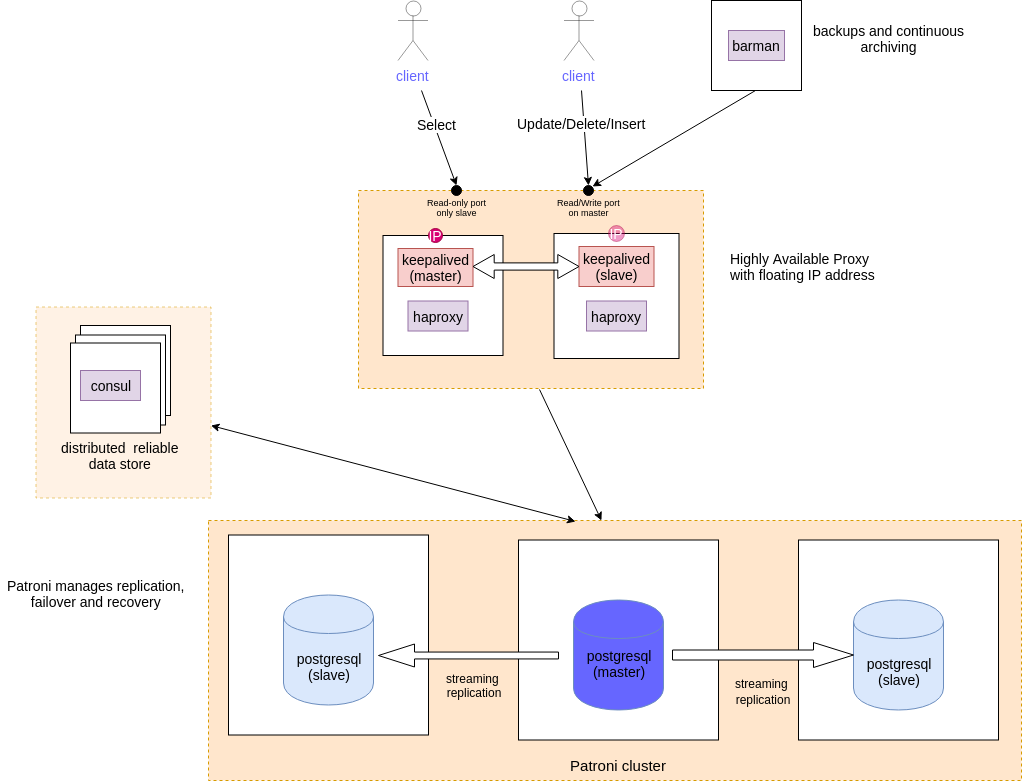
Overall we believe the final technology choices and implementation will provide a reliable HA solution, and that developing using infrastructure-as-code principles and a test cluster that we could easy rollback allowed a very smooth migration of a live production database.
Footnotes
-
In our tests, we verified that extremely large write commits can be a problem for the
synchronous modecase when there is just a standalone master. In this case, when a slave is restored, it will have problems to synchronise because thewrite-ahead loggingfile will not have the data anymore. So, a manual recover has to be performed. We assume that, if necessary, thewrite-ahead loggingfile size can be tuned as well as themaximum_lag_on_failoverwhich defines how far a slave can be from the master for theautomaticfailover to happen. ↩ -
According to Barman “When backing up from a standby server, the only way to ship WAL files to Barman that is currently supported is from the master server.” ↩
-
We used the patroni role developed by Kostiantyn Nemchenko plus our own additional role to perform some custom configuration. ↩