
Introduction
Findmypast and its sister site; the British Newspaper Archive (BNA), are served by a web of microservices operating across multiple Kubernetes clusters. A number of our microservices rely upon a back-end database, and although we do operate other database technologies (MSSQL, MongoDB etc.), Postgres is our de-facto standard for relational databases.
When the DevOps team first realised the need to upgrade all of the database nodes to the latest Postgres version, we operated a total of twelve production Postgres databases, each running on their own dedicated Ubuntu Linux virtual machine (VM). Running on standalone VMs allows for separation of concerns, and limits the ‘blast radius’ of issues and failures should they occur. All VMs are managed by our Hyper-V cluster, and backed up regularly by Veeam. In addition to this backup method we operate Barman, which takes a full backup of all production Postgres database hosts nightly, and continuously receives WAL (Write Ahead Log) updates.
We operate a a similar number of staging / integration / utility Postgres databases. Unlike the production databases these are (mostly) co-located on a single host, given the reduced storage and performance requirements of these databases.
Existing Processes
We manage Postgres installations and configuration through Puppet, pinning the installed version of Postgres. After the initial deployment we were not actively upgrading the Postgres version running on the hosts. Upgrades of the production databases were instead only undertaken by the feature teams (those teams that manage our micro-services), or by us when requested by the feature teams. This meant that we had a variety of Postgres databases deployed to production, between versions 9 and 14 (the latest supported version at the time). It also meant that the Production Postgres versions differed from their respective staging / integration database. We knew this situation, as well as the approach to upgrades was bad practice, and wanted to reset by normalising all Postgres database deployments to the latest supported version.
Benefits of Upgrading
We understood that upgrading all database hosts to the latest Postgres version would bring with it several benefits:
- Patch all known security issues and bugs.
- Reduce the support burden of managing multiple versions, particularly the quirks present in older versions.
- Generally improve database read/write performance.
- Reduce the friction when feature teams wanted to leverage new database features.
- Give us an opportunity to migrate databases to hosts running the latest Ubuntu Linux OS distribution.
Preparing for the Production Upgrades
In early July 2022 we set about identifying if there were blockers to upgrading any of the twelve production databases to Postgres 14. We reviewed the release notes for each major release since 9.5, and were able to identify that there were no deprecation / configuration changes that affected our Postgres database deployments. We put this to the test by upgrading the Postgres version of the staging database host from 11 to 14, meaning all databases on this host would be instantly migrated to the latest version of Postgres. We left this to “bed in” for some time, which proved to us and importantly the feature teams, that all micro-services that utilised a Postgres database could function with Postgres 14.
However, as the staging databases sizes were small (~100-500MB), the data stored in them could be re-generated on-demand or discarded. Therefore, the upgrade / switchover was a simple and near immediate change. We knew that this approach would not be applicable for our production databases given their size, the need to limit downtime, and of course the need maintain customer data. Therefore we went to work planning the upgrade process in detail.
Planning the Upgrades
Having identified that all microservices that utilised a database could operate with a Postgres 14 database, we went about planning the work that would be involved to upgrade. We knew that we wanted to get this work done as quickly as possible, due to the fact that we had de-prioritised this work for some time. As we work within a team practising an agile methodology with regular refinement sessions, the planning of how were going to tackle this did not take long, and by the end of July 2022 we had an epic and plan that broke down as follows:
- Identify how we can upgrade each Postgres versions (9-13) we were operating to Postgres 14, and document these in a “playbook” style.
- Identify whether or not all databases needed to be maintained (there were a number of services that were initially flagged as no longer required for production).
- Conduct the upgrades on each production database VM.
- Where necessary, upgrade the underlying Ubuntu Linux OS.
- Cleanup our Puppet & Ansible code bases of Patroni (HA Postgres) references that we had experimented with, but were no longer planning on implementing.
- Improve the documentation of our Postgres Barman backup configuration.
Having planned out the stories, and refined them as a team, we surmised that we could complete the entire epic of work within a single three month quarter. We scheduled this to occur pretty much immediately during the upcoming quarter, between August and October 2022.
Identifying the Upgrade Processes
Identifying how we would need to upgrade each production database was the first major task we needed to complete. Given that we were running a variety of Postgres database versions between 9.5 and 13.1, we were aware that there may be specific procedures necessary to move between versions, in order to maintain data integrity and limit downtime.
After initially reviewing some upgrade process documentation for a variety of Postgres versions, we used a number non-critical Postgres databases to refine our upgrade procedures. What came out of upgrading these non-critical Postgres databases were three approaches for the production upgrades:
- A schema transfer of the database to a new host, and replication of data via Write Ahead Logs (WAL) publication and subscription. a) This was only possible for databases on Postgres 10 or greater
- A complete transfer of the database schema and data, via
pg_dumpallto a new host. - An in-place upgrade on the existing host.
Each approach had drawbacks, benefits and limitations. For instance the first approach, incurred very little downtime, but would only be an option for Postgres databases that supported WAL publication. The second two options, would incur downtime dependant on the size of the underlying database, but was an option regardless of the database Postgres version.
Despite the differences each approach shared common features:
- Postgres installation and configuration would be defined and applied by Puppet.
- Barman backups of the databases (both existing and new) should be disabled during the upgrade.
- Prometheus monitoring of any new database hosts would need to be re/configured (we do this via an Ansible playbook).
- Database state (including the publish and subscription progress) could be monitored through a pre-defined Grafana dashboards, or queries directly against the database.
Running the Upgrades
In practice, the existing Postgres version, and the need to limit downtime for the majority of production services, were the most limiting factors when choosing the approach for upgrading the databases.
In total we upgraded eleven production databases from various Postgres versions up to version 14. Six were upgraded from Postgres 9.5, four from version 11, and one from version 13.1. One database was identified as no longer required, and the host was shut down. We completed all upgrades in just over six weeks (three sprint cycles), picking them up as and when time allowed alongside a number of other work streams, as well as on-boarding several new members of the DevOps team.
The majority of the databases were upgraded by creating a new host and conducting a complete transfer of the database (via pg_dumpall), this was possible only due to their relatively small size that ensured they were never down for very long. However when it came to our larger databases (>1TB in size), these had to be upgraded using a schema transfer of the database to a new host, followed by replication of data via WAL publication / subscription.
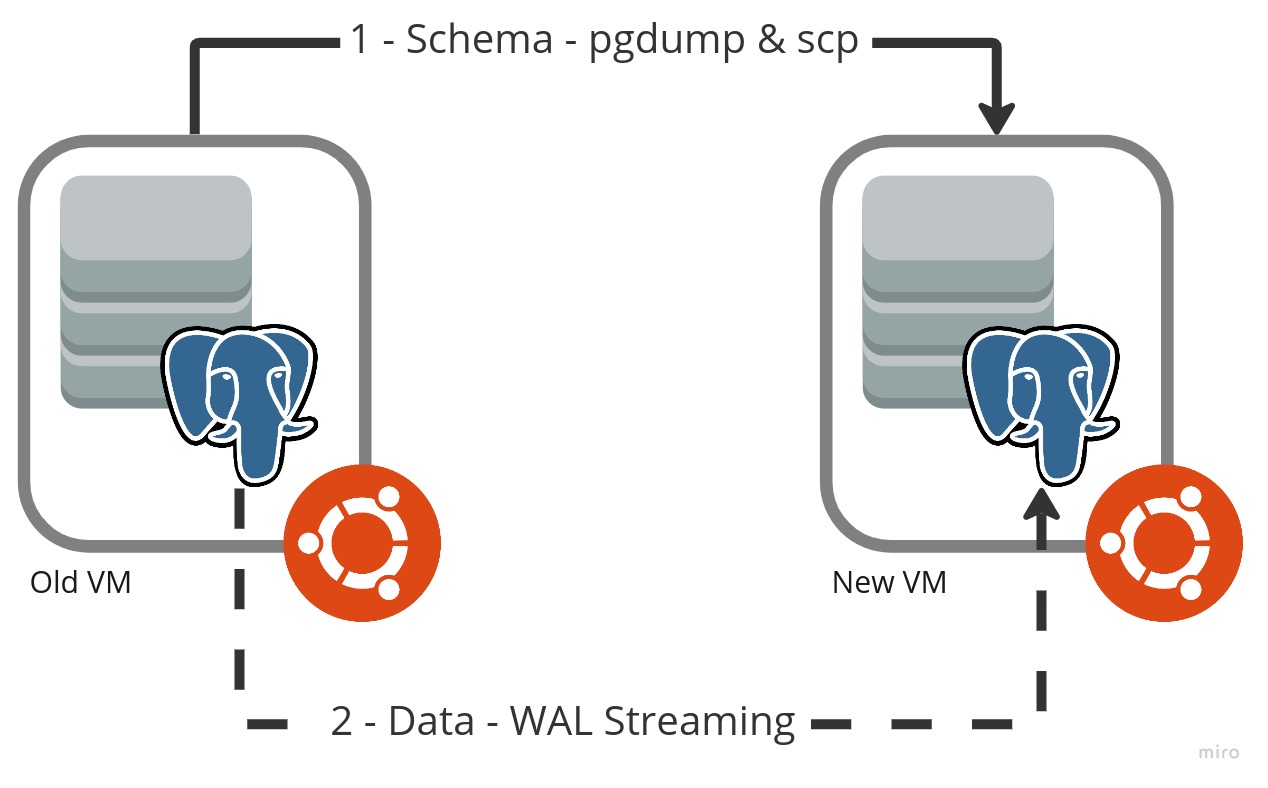
For the larger databases the WAL replication took in the order to two-to-three days to complete, as we were bottlenecked by the hardware to ~10MB/s transfer speeds between database hosts, which was acceptable, if not a little frustrating at times. The subscription and replication added practically no overheads on the database hosts, and it was easy to monitor through both psql commands and Grafana (see example below):

However it was with this method that we faced the largest number of issues, relating both to our processes and inherent behaviours / shortcomings in the tools and commands used:
- New VM location in Hyper-V - To avoid network bottlenecks between Hyper-V hosts, we had to colocate the VMs on the same Hyper-V host and enable NIC acceleration.
- Subscriptions cannot be ungracefully stopped - Subscriptions to a publication must be gracefully paused in order to pickup where they left off, otherwise the subscription will have to be re-built. We realised this when the disk on one of the new databases hosts required extending.
- Stalled Subscriptions - Postgres logical replication does not handle Primary Key conflicts (a known issue), and will repeatedly surface
ERROR: duplicate key value violates unique constraint "<table_name>_pkey"logs, whilst not inserting data in to the target database. The resolution here was to undertake the following process:- Pause the subscription -
ALTER SUBSCRIPTION <subscription_name> DISABLE; - Clear all data from the target table -
TRUNCATE TABLE <schema_name>.<table_name>; - Drop the constraint documented in the error message -
ALTER TABLE <schema_name>.<table_name> DROP CONSTRAINT <constraint>; - Repopulate the table -
ALTER SUBSCRIPTION <subscription_name> ENABLE; - Wait for the copy phase of the synchronisation to complete
- Pause the subscription -
ALTER SUBSCRIPTION <subscription_name> DISABLE; - Cleanse all duplicates -
DELETE FROM <schema_name>.<table_name> T1 USING <schema_name>.<table_name> T2 WHERE T1.ctid < T2.ctid AND T1.<constraint_column> = T2.<constraint_column>; - Restore the constraint (the constraint definition can be found in the schema dump) -
ALTER TABLE ONLY <schema_name>.<table_name> ADD CONSTRAINT <constraint> PRIMARY KEY (<constraint_column>); - Restart the synchronisation -
ALTER SUBSCRIPTION <subscription_name> ENABLE;
- Pause the subscription -
- Missing Database Grants - Older versions of
pgdumpandpgdumpallcommands do not replicate database levelGRANTcommands, which need to be manually generated after the dumps are restored. - Missing user-defined sequence indexes - Logical replication using the publication / subscription model does not replicate user-defined sequence indexes. To resolve we had to identify all user-defined sequences, and manually update each index to a value greater than the largest ID used in the relevant table.
We did have to restart the replication a couple of times when above issues were identified, though thankfully no incidents occurred due to these issues. All gotcha’s and workarounds were documented within our upgrade playbook and troubleshooting guides for future reference. Later upgrades were much smoother thanks to this feedback loop.
The only issue encountered with the in-place upgrade on an existing host (completed for the Postgres 13 database host), was in relation to the Barman backup configuration. After the upgrade, the Barman backups begun to fail with the error systemid coherence: FAILED (the system Id of the connected PostgreSQL server changed, stored in "/var/lib/barman/<BACKUP_HOST>/identity.json") surfacing. As the error message suggests we had to manually update the target Postgres version within the Barman database, and also clear out any failing WALs in the var/lib/barman/<BACKUP_HOST>/errors/ directory of the Barman backup host.
What we Learned
Upgrading multiple Postgres versions in one go was initially seen as a daunting prospect. Thankfully due to our configuration being deployed by Puppet and our fairly simple Postgres configuration, we did not hit any major issues or blockers. Those issues we did encounter were resolvable, and the breadth of the workarounds did not require us to vastly change our initial approach.
At the epic’s inception we were not aware of the limitations (e.g. not transferring database level privileges (bug report)) of the pgdump and pgdumpall commands in earlier Postgres versions, and now have a greater appreciation of how and when specific options should be used.
Similarly, the increased focus on our Postgres environment enabled us to engage with feature teams regarding their ownership of databases. As a result database hosts that were no longer being used by production services could be dropped.
It gave us a better insight in to Barman, our Postgres backup solution, and gave us the time and space to improve our knowledge around this. This has lead us to plan future work to:
- Upgrade Barman to version 3 (the latest major version at the time of writing), in order to support backups of Postgres 15 databases.
- Reduce our Recovery Point Objective (RPO) by leveraging the
barman-wal-archivemethod of WAL streaming (documented here).
We also identified several shortcomings with our processes in relation to managing and provisioning Postgres databases, and we will look to make the following process improvements:
- Take a pro-active approach to maintaining databases on the latest supported version. In practice this means that we will schedule a regular review of Postgres releases to ensure that we are aware of upcoming releases, and any deprecations or impacts.
- Attempt to automate the creation of new Postgres databases for developers. We are initially thinking of a REST endpoint (extending one of our internal services) that will provision a basic database host with fixed hardware and Postgres configurations.
What’s Next?
Shorlty after completing the upgrade of all production Postgres databases a new major version (15) was released! We will start to schedule these upgrades for a future quarter, but have already had interest from feature teams to upgrade to this version, due to its ability to support row level filtering in replications.
Thank You
We hope the above has given you a taste of how the DevOps function at Findmypast operates, the type of work that we undertake, and our approach. We are always looking for engineers to join our team so if you’re interested contact us or check out our current vacancies.