
Our journey along the Kuberentes (K8s) road continues with the story of how we diagnosed and solved random, intermittent DNS lookup failures between K8s pods and also between pods and services external to our K8s cluster.
The problem
Findmypast have 80+ microservices running in the K8s cluster each of which have at least 3 pods running per service. Many services have horizontal auto scaling enabled, which means the service may have many pods running depending on load. We don’t have a huge K8s cluster, so it was surprising to see NodeJS services starting to log messages such as:
Error: getaddrinfo EAI_AGAIN some-external-host
Or
RequestError: Error: getaddrinfo EAI_AGAIN k8s-service
And, it wasn’t just the NodeJS services that logged domain lookup failures, our Elixir based services were also complaining:
Service HTTP Error: nxdomain, Message :nxdomain, Url: https://www.findmypast.ie
Engineers were raising the issue since these domain lookup errors were affecting their error rate metrics and, in some cases, their service alerts were firing.
Also, we were also getting reports that communication between services was causing issues; in particular one service that we call Titan Marshal, was complaining about timeouts when talking to another service called Flipper. Oddly, we didn’t see the same behaviour when Titan Marshal was calling other services. We saw timeouts, but not on the same scale. At the time, the timeouts and the DNS lookup failures seemed unrelated.
Flipper is one of our central services that receives a lot of traffic - it manages our feature toggles and typically gets ~150 requests per sec. Services use Flipper to get the feature toggle state for a user - a failure to return the toggle state means that a user could, conceivably, get two different toggle states during their visit. The feature toggle is used to allow/deny access to certain features on the site, so a user seeing two different states could get different behaviour or features. In fact, we did see some (small) evidence of that happening on production.
So, services were intermittently timing out or failing to resolve a DNS lookup. This was particulary bad with services calling Flipper, so it was time to dig deeper.
Gathering data - DNS lookup failures
Before we dig deeper, let’s have a (simplified) look at how the DNS lookup is handled in K8s before the fix:
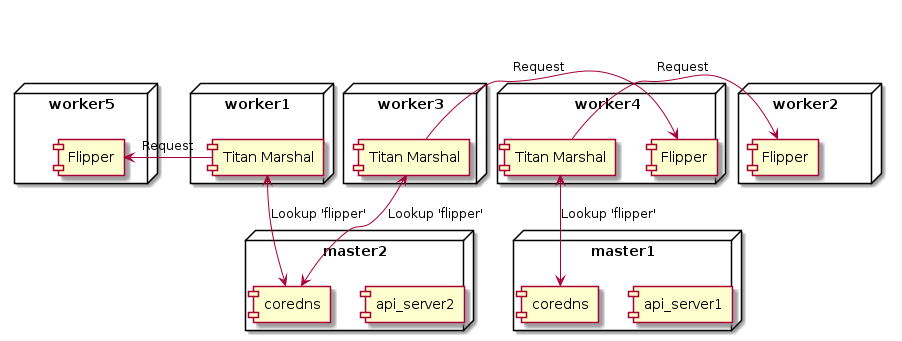
DNS lookup is handled by the coredns pods. We currently have two of these pods running, both are running on master nodes. When a pod (Titan Marshal in this instance) sends a HTTP request to another service (Flipper) then a DNS lookup is sent to the coredns pods which will return one of the Flipper service pod IPs.
With that in mind, we first looked at the logs from the coredns pods. After all, if we are getting domain lookup failures then these should be coming from the DNS service, right? Well, wrong it seems. coredns logs were not reporting any particular problems and the coredns_dns_request_duration_seconds_bucket Prometheus metric exported by the coredns pods were reporting <6ms response times for the 99th percentile. While we didn’t immediately rule out coredns, it was removed from the list of top suspects.
Next, we looked at the distribution of the DNS lookup failures but these were random. For example, a service might log DNS lookup failures that would last 60 seconds or so, but other services were fine. (Or, rather they would report DNS failures but at a different time.) However, when a service did start to log the failures, the failures were not associated with one pod, but spread across a number of pods. Pods were spread across worker nodes, so the failures were not localised to a particular worker. But, other pods on those worker nodes weren’t affected, which suggested that it wasn’t an inherent issue with the node networking but something else.
We also noticed that some services suffered from the DNS lookup problem much more than others. Some services hardly suffered at all. Again, this suggested that the issue was not inherently due to K8s networking but, perhaps, more to do with the docker image or the service configuration. Services used different docker base images - e.g.: node:slim, node:lts-slim or node:alpine images. Some services specified a specific version of the Docker image, like elixir:1.6.5-alpine or elixir:1.7.4-alpine. We were aware of K8s issues with DNS in Alpine and DNS issues with Alpine images but there was no obvious reason as to why one alpine image, for example, would fail while another would work almost flawlessly. Even with the same docker base image, we had discrepancies across services. Thoughts were turning toward configuration with the particular service. We knew that NodeJS, in particular, may have performance issues with DNS lookups:
Though the call to dns.lookup() will be asynchronous from JavaScript’s perspective, it is implemented as a synchronous call to getaddrinfo(3) that runs on libuv’s threadpool. This can have surprising negative performance implications for some applications, see the UV_THREADPOOL_SIZE documentation for more information.
Also, it seems that NodeJS does not provide caching of DNS lookups. Both Titan Marshal and Flipper are NodeJS services, so all DNS lookups would end up at the coredns pods, even if request the same endpoint multiple times a second. This might explain why we got DNS lookup failures bunched around the same time.
Given the DNS cache issue, and the thread pool performance issue we suspected that the reason that some of the NodeJS services were failing was due to configuration. We also suspected that the Elixir services were failing for similar types of reasons, but didn’t dig deeper into the Elixir side of things.
To summarise:
- DNS lookups affected both NodeJS and Elixir services;
- The lookup failures affected multiple pods in a service, but did not affect other pods;
- Some services rarely failed with DNS issues, which suggested the issue was local to the service;
- NodeJS had performance issues both with the
UV_THREADPOOL_SIZEas well as no caching of the DNS reply; corednswas responding quickly and not reporting problems
At this point, thinking was that something was going on inside the Docker image that prevented the outgoing DNS request ever reaching coredns or we had some subtle issue with the Flannel network layer inside of Kubernetes.
Gathering data - Timeouts
At the same time we were looking into the DNS lookup failures, we were also digging into the 500ms timeouts between Titan Marshal and Flipper. Specifically, why so many timeouts to Flipper when calls to other services from Titan Marshal hardly ever failed?
The Flipper service is well instrumented, incoming requests are instrumented, all outgoing HTTP calls are instrumented and all the figures showed the Flipper was performing well within its Service Level Objective. The timeout from Titan Marshal to Flipper is 500ms, but we rarely saw latency spikes that took that long in the Flipper dashboard.
We knew we were having DNS issues, so we decided to instrument how long the DNS lookup and TCP connect times were taking for Flipper. This RisingStack article had a good explanation of how to get these timings out of a NodeJS HTTP request, which we added to Flipper and exported the timings as Prometheus metrics.
The results were…surprising. It appeared that Flipper could sometimes take up tp 8 seconds to perform a DNS lookup. Even during “normal” operations, the 99th percentile latency of the DNS lookup was ~128ms. We added the same TCP network instrumentation to other services to see if these services were exhibiting the same behaviour, but it appeared that only Flipper had this issue.
The DNS timeouts was the reason why Titan Marshal was timing out calling to Flipper. The graphs below shows the results of Titan Marshal calls to Flipper (via Apollo engine stats) and the TCP instrumentation from Flipper. The increase in DNS lookups times correspond nicely with the timouts recorded by Titan Marshal.
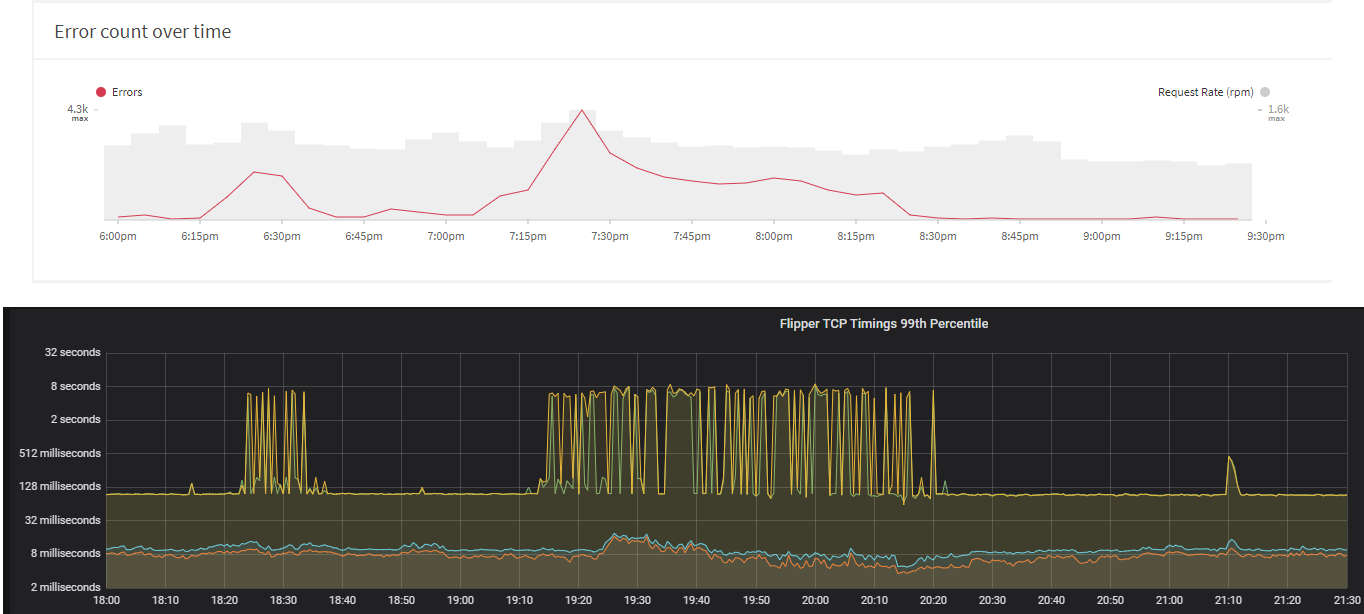
So, while we knew the reason why Titan Marshal was timing out, that still didn’t explain why only Flipper was taking so long to perform the DNS lookup. (Also, it doesn’t explain why the long DNS lookup times weren’t reflected in the request duration metrics produced by Express Prometheus Bundle module. That requires further investigation.)
We compared the base Docker image of Flipper with other NodeJS services that didn’t have the DNS lookup issue; even when using the same base image and the same versions of dependencies, Flipper still took way longer than other services to perform the DNS lookup. At this point we began to suspect that the long DNS lookup times and the DNS lookup failures were symptoms of an underlying problem within the K8s cluster.
Time to dive deeper…
CPU throttling in K8s
Investigation into poor server performance lead us to an number of interesting articles about how Kubernetes manages the CPU request and the CPU limits for a pod. Let’s take a look at what K8s documents about CPU request and CPU limits:
When using Docker:
- The
spec.containers[].resources.requests.cpuis converted to its core value, which is potentially fractional, and multiplied by 1024. The greater of this number or 2 is used as the value of the--cpu-sharesflag in thedocker runcommand.
- The
spec.containers[].resources.limits.cpuis converted to its millicore value and multiplied by 100. The resulting value is the total amount of CPU time that a container can use every 100ms. A container cannot use more than its share of CPU time during this interval.
The CPU limit is subtle - essentially if you specifiy a CPU limit for your pod, that value will be used to calculate how much time your container can use within a 100ms period - once the time is up the container is throttled until the next period. This CPU throttle can degrade the performance of latency critical services. A quick “fix” for this issue is too simply remove the CPU limit for the service. While that helped, a little, it didn’t really sort the underlying problem of slow DNS lookup times.
For more information on CPU throttling in K8s, see:
- https://medium.com/omio-engineering/cpu-limits-and-aggressive-throttling-in-kubernetes-c5b20bd8a718
- https://github.com/kubernetes/kubernetes/issues/51135#issuecomment-373454012
- https://www.youtube.com/watch?v=UE7QX98-kO0&feature=youtu.be&t=3560
The latter YouTube video is an deep dive into Linux CPU scheduling with Dave Chiluk. Long story short, a scheduling bug in Linux has been fixed with release 5.4 of the Linux kernel.
Linux networking race conditions
Further reading and digging into various connection and DNS timeouts led us to other articles with similar DNS and connection timeout issues. We tried some of the simplier solutions too see if they would help the DNS lookup, but still no joy. Some solutions involved patching tc, libc, musl, etc which was not an avenue we wished to go down without knowing if the patches would really solve the problem.
However, we did determine that the Linux kernels on our K8s hosts appear to be suffering from a DNAT race condition - the race condition has been fixed in 5.x of the Kernel.
For more information on the DNAT race condition:
- https://www.weave.works/blog/racy-conntrack-and-dns-lookup-timeouts
- https://github.com/kubernetes/kubernetes/issues/56903
- https://blog.quentin-machu.fr/2018/06/24/5-15s-dns-lookups-on-kubernetes/
- https://tech.xing.com/a-reason-for-unexplained-connection-timeouts-on-kubernetes-docker-abd041cf7e02
- https://github.com/weaveworks/weave/issues/3287
The solution
The solution was pretty straightforward - we installed a K8s cluster add-on called Node Local DNS cache. This runs on each of the K8s worker nodes and caches DNS requests from the pods on that particular node. DNS lookups now look like this:
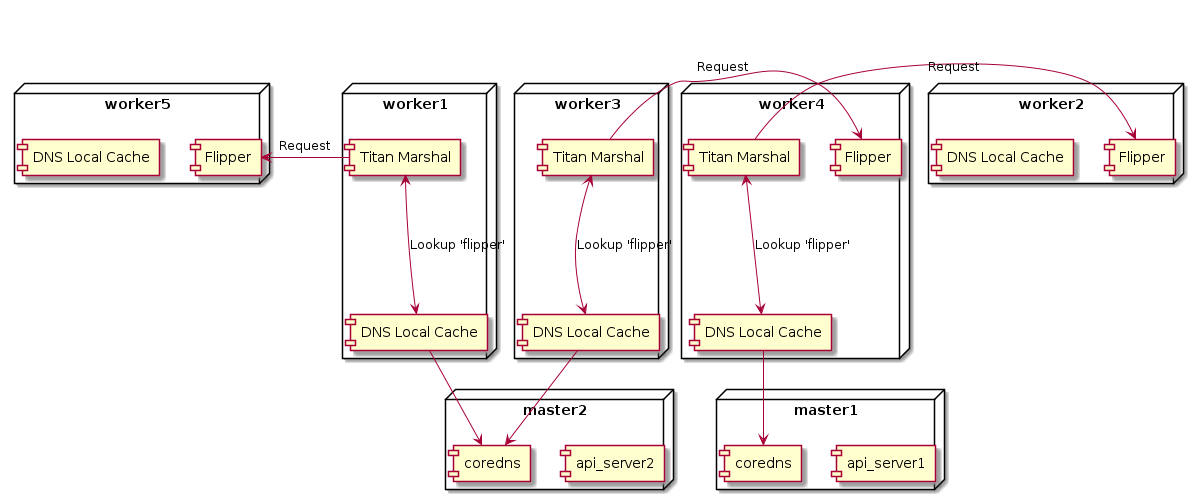
Instead of (potentially) hopping out to another worker node to get DNS resolution, pods query the DNS on the worker node itself. Since this also caches DNS lookups, the end result is faster DNS resolution for pods. Installing the DNS cache was easy and, even better, no changes to existing services were required to use the DNS aside from a pod restart.
Since we’ve added the cache we’ve seen:
- No instances of domain resolution failure.
- Flipper DNS lookup times are comparable with other services.
- Large reduction in Titan Marshal to Flipper timeouts
Summary
Debugging K8s issues like this can be hard, especially when the problems are intermittent. Instrumentation of your service is invaluable when diagnosing issues like this. After all, who’d have thought that DNS lookup would be so slow (for one service!). “If it moves, instrument it” is a well known mantra and one we’ll continue to take on board for the future.
The DNS Local Cache solution is a mitigation, we haven’t really got to the bottom of the various issues, but the suspicion is that the DNAT network race condition is contributing to, if not the underlying cause of, the issue. Our next stage is to upgrade Linux on all the K8s hosts, at the very least that’ll fix the CPU throttle and the DNAT bugs.