
Ahh, one of the big questions in our industry right now… How do I take a monolith and refactor it into Microservices? Where the heck do you even start? Assuming you’re operationally ready for Microservices migration can be an arduous task. This article covers our approach to identifying and breaking off parts of our monolith.
The road we’re walking isn’t a new one, it’s a well trodden path mapped out by Sam Newman who literally wrote the guidebook on Microservices. Borrowing concepts and techniques from Domain Driven Design we start by running event storming workshops which help us identify our business subdomains (or bounded contexts). Following mapping out the subdomains we annex areas of our monolith in tandem with adding complete functional test coverage that captures all associated business rules. With strict separation of concerns in place and the safety net of tests we are now ready to migrate our associated database. Given that our subdomain now has sole ownership over its data it’s now time to create our new Microservice reusing our functional tests. Finally we look to remove any redundant code from the monolith and then you’re done!
How do we identify our business subdomains?
Let me ask you a question. Assuming you have a monolith if you were to imagine your monolith in pictorial form what would it look like?
Like this?
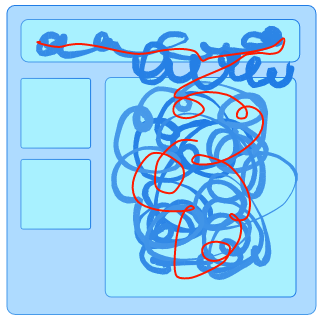
Or this?

At the beginning of re-architecture we run Event Storming workshops which greatly aide us to identify the various business subdomains that we want our software to model. Event Storming is described by its inventor Alberto Brandolini as
… a workshop format for quickly exploring complex business domains.
It’s a new technique, only surfacing in late 2013, but has become popular in Domain Driven Design circles as a way of capturing actors and events within a system. We’ve run it a couple of times and have found great value in the results it has given us.
Once we have our ideal subdomains mapped out we can start refactoring the code within the monolith into well defined chunks. The intent of the refactoring is to annex complete services within the monolith. The next stage of the monolith might look a little bit like this with a couple of annexed internal services but still a good portion of spaghetti code.

At this point you might be thinking but I don’t want to write lots of code in my monolith, that’s why I’m moving to Microservices. If that’s the case then read on.
This seems like a lot of work to do to an application that we want to replace, why don’t we just start with writing the services from scratch?
This is such a good question and one that I find challenging to argue against. There’s a reason we’re moving to Microservices and that’s because our technical debt is wildly out of hand in our monolith. Writing and reasoning about code in the monolith is a monumental task and it just seems so tempting and easy to write a new service. On the surface of it writing a new service seems much simpler but I’ll try to explain, by digging a little deeper, why I think you should start in the monolith.
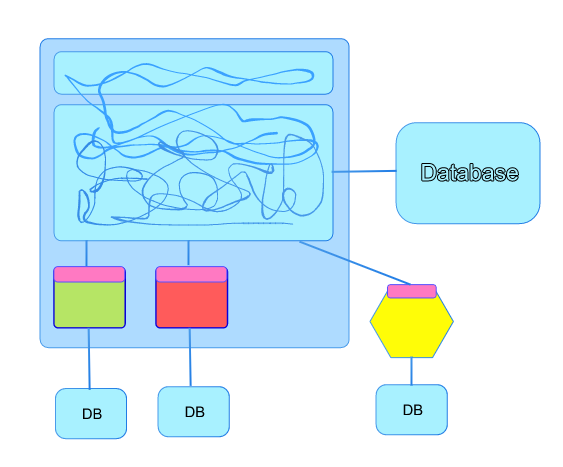
Here we have our monolith. The red line represents a chunk of functionality that could be refactored into a new subdomain or written as a new service. As you can see it’s intertwined with every part of the system from the view down to the database.
Imagine that we write a new service from scratch that connects to the same database like so. The new service completely replaces the functionality depicted by the red squiggly line in the diagram.
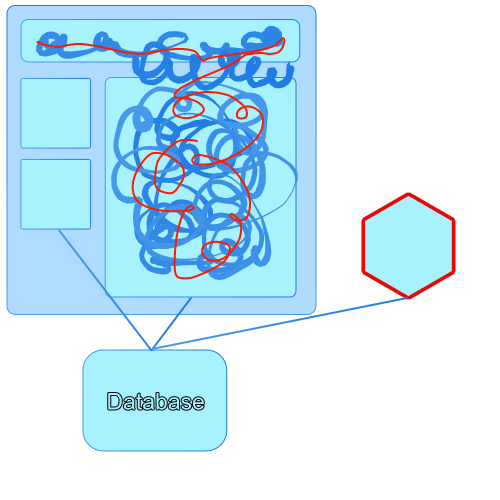
This poses a few interesting questions. If you change the schema of the database will your new service break if it relies on that schema? Can you be one hundred percent sure you’ve captured all the business rules and implemented them like for like replicating all functionality from the monolith? How do you get rid of that squiggly red line that represents a thread of functionality and replace it with calls to the new service? Can you be sure you’ve found everything and there’s nothing in the monolith making sneaky changes to the data managed by your new service?
Quite frankly I don’t want to be the one answering those questions when something inevitably goes wrong and you’re adversely affecting the company’s revenue stream and irreparably damaging delicate customer relationships.
With this in mind let’s look at an alternative approach.
How do we create a subdomain within our monolith?
Assuming you agree with me that we should start in the monolith we’re back to the point of having our desired subdomains identified through Event Storming. The next step is to isolate those subdomains through refactoring into annexed internal services. This is painstaking work and a substantial amount of rigour is required in performing refactoring on such a massive scale.
Imagine a big messy monolith like this with lots of coupling and shared dependencies. We start off by pulling on the threads in the monolith and unpicking and unwinding them out into annexed services.
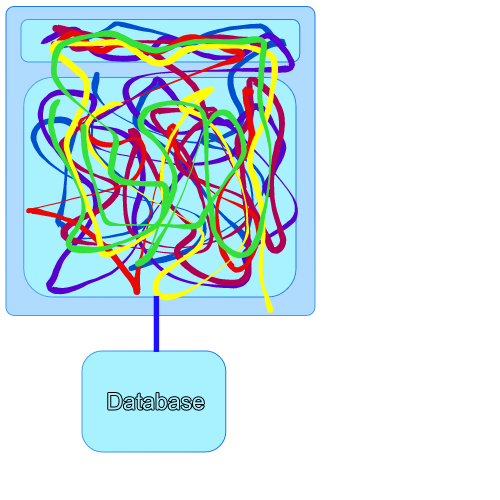
Each annexed service should have a single API to access the public functions of the subdomain. This is the single point of contact with the monolith with all other code being encapsulated and hidden within the subdomain. With each new subdomain that we model we also aim to capture all the business rules in Cucumber tests which live with it. These tests are full functional tests written in ubiquitous language at an API level so that they are portable and reusable when we come to extract a Microservice. Eventually you will hopefully find yourself in a state depicted by the diagram below.
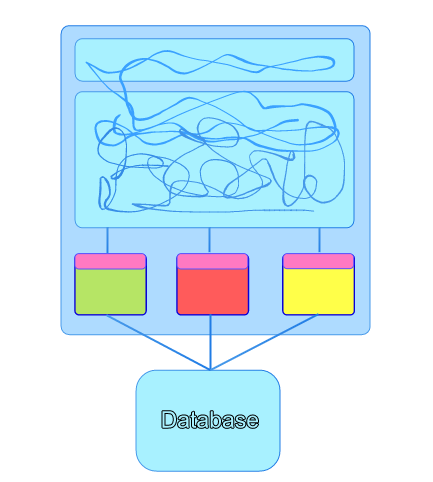
At this point we’re doing a lot better but we still have a shared database and we still want to enforce this separation of concerns with a hard infrastructural boundary. Next, onto the database.
How do we tease apart the database?
You’ll have to find a way to break your database into chunks if you want to break off a chunk of the monolith and not have a shared database dependency. There’s a few techniques you can use here. In this example I’m assuming a SQL database migrating to a SQL database but there’s many other options out there for migrating from SQL to NoSQL that I won’t cover here.
One approach we’re using is to slowly migrate data within your main database. Making non-destructive changes until you have a set of tables under a new schema that reflect the schema you ideally want. You are now in the situation of your data being completely segregated from the main database. Your annexed service is connected to those new tables under the separate schema. Finally you can migrate the schema to a new database and you might end up with something like this.
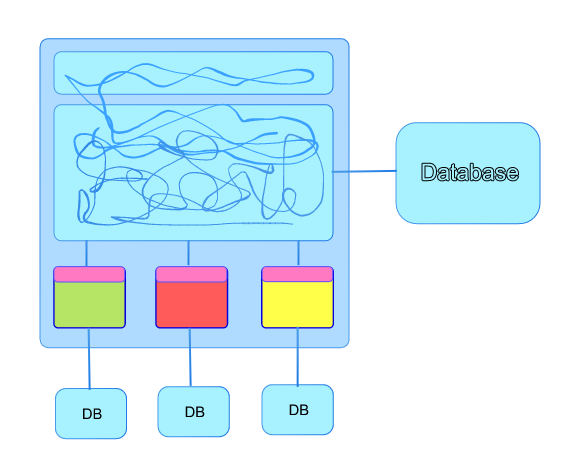
The unused columns and tables in the main database can be deleted over time making sure to give teams like analytics time to update their models to reference the new database if they’re reliant on the existing data and schemas.
Finally, how do we extract a Microservice from the Monolith?
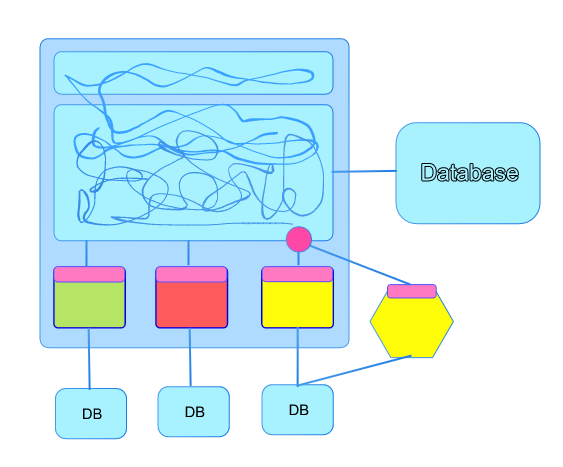
At this point you’ve got a couple of options. You can take your existing code and move that to run under a new project and repository. In our case we’re moving from C# to Elixir for our standard server technology. In the diagram below you can see a service that has been implemented to support the same API as the service within the monolith. This is only possible in a safe way when you have a full suite of functional tests that capture all the business rules. You can develop against these and once they’re all passing that should give you confidence that you’ve implemented a like for like service.
The pink dot represents the forking point and we’re looking to use some sort of feature toggle to perform a canary release. This allows us to test that the new service stands up to real users. A great overview of this technique has been written up by github (http://githubengineering.com/move-fast/) with the usage of their scientist library.
Hopefully everything is going well and you can move to using the new service for one hundred percent of users. This now represents the state of play in your system.
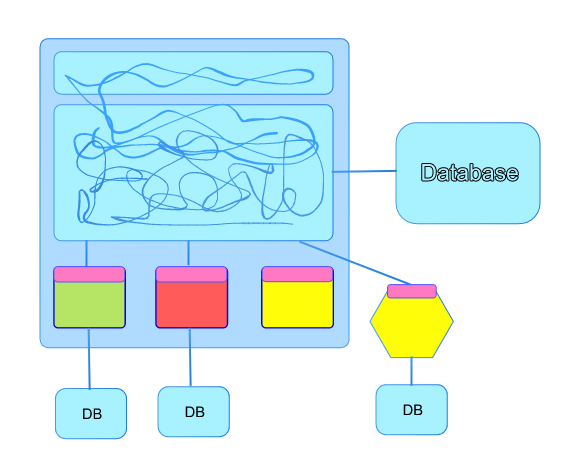
The only thing left do is to delete the redundant code from the monolith and you’ve broken out your first Microservice.
That’s it, you’re done! I sincerely hope you find this useful, I don’t want to be prescriptive, this is just our approach right now which will undoubtedly change as we learn more by doing further monolith refactorings and Microservice extractions.
We build our software with NodeJs, ReactJs, Elixir and Phoenix. If you like the sound of what we’re doing here please apply as we’ve got open software engineering positions in both Dundee and London.